In my dissertation, I extended multinomial processing tree (MPT) models to include response times. MPT models are very useful to disentangle multiple underlying processes based on observed response frequencies. However, these models are limited to categorical data, which prevents a direct application to continuous variables such as response times. 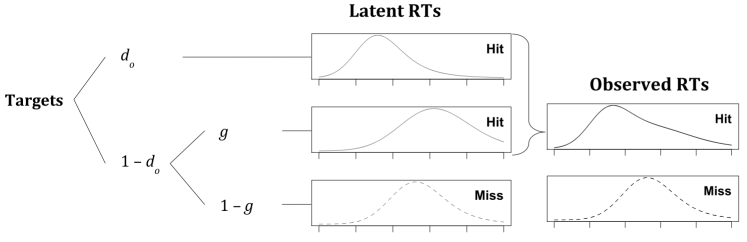
MPT-RT Models
MPT models directly predict that observed RT distributions are mixtures of latent RT distributions. To estimate these latent distributions (e.g., the RT distribution of recognition in memory tasks), we proposed to categorize responses from fast to slow into several bins (similar to a histogram). This results in a new, extended MPT model that allows to estimate the relative speed of the hypothesized cognitive processes. For details, see:
-
![[PDF]](https://www.dwheck.de/wp-content/plugins/papercite/img/pdf.png) Heck, D. W., & Erdfelder, E. (2016). Extending multinomial processing tree models to measure the relative speed of cognitive processes. Psychonomic Bulletin & Review, 23, 1440–1465. https://doi.org/10.3758/s13423-016-1025-6
Heck, D. W., & Erdfelder, E. (2016). Extending multinomial processing tree models to measure the relative speed of cognitive processes. Psychonomic Bulletin & Review, 23, 1440–1465. https://doi.org/10.3758/s13423-016-1025-6
[Abstract] [BibTeX] [Data & R Scripts]Multinomial processing tree (MPT) models account for observed categorical responses by assuming a finite number of underlying cognitive processes. We propose a general method that allows for the inclusion of response times (RTs) into any kind of MPT model to measure the relative speed of the hypothesized processes. The approach relies on the fundamental assumption that observed RT distributions emerge as mixtures of latent RT distributions that correspond to different underlying processing paths. To avoid auxiliary assumptions about the shape of these latent RT distributions, we account for RTs in a distribution-free way by splitting each observed category into several bins from fast to slow responses, separately for each individual. Given these data, latent RT distributions are parameterized by probability parameters for these RT bins, and an extended MPT model is obtained. Hence, all of the statistical results and software available for MPT models can easily be used to fit, test, and compare RT-extended MPT models. We demonstrate the proposed method by applying it to the two-high-threshold model of recognition memory.
@article{heck2016extending, title = {Extending Multinomial Processing Tree Models to Measure the Relative Speed of Cognitive Processes}, author = {Heck, Daniel W and Erdfelder, Edgar}, date = {2016}, journaltitle = {Psychonomic Bulletin \& Review}, volume = {23}, pages = {1440--1465}, doi = {10.3758/s13423-016-1025-6}, abstract = {Multinomial processing tree (MPT) models account for observed categorical responses by assuming a finite number of underlying cognitive processes. We propose a general method that allows for the inclusion of response times (RTs) into any kind of MPT model to measure the relative speed of the hypothesized processes. The approach relies on the fundamental assumption that observed RT distributions emerge as mixtures of latent RT distributions that correspond to different underlying processing paths. To avoid auxiliary assumptions about the shape of these latent RT distributions, we account for RTs in a distribution-free way by splitting each observed category into several bins from fast to slow responses, separately for each individual. Given these data, latent RT distributions are parameterized by probability parameters for these RT bins, and an extended MPT model is obtained. Hence, all of the statistical results and software available for MPT models can easily be used to fit, test, and compare RT-extended MPT models. We demonstrate the proposed method by applying it to the two-high-threshold model of recognition memory.}, osf = {https://osf.io/msca9}, keywords = {heckfirst,heckpaper} }
Recognition-Based Decisions
We applied this MPT-RT method with respect to the recognition heuristic in the field of judgment and decision making. In the domain of memory-based inferences, people have to decide which of two options is larger on some criterion (e.g., which city is larger). Often, people choose the city they know. To disentangle whether other information (e.g., whether the known city has an airport or metro) also enters the decision, we extended the r-model (an MPT model) to response times. Thereby, we could show that people were actually faster when considering more, recognition-congruent knowledge. For details, see
- Heck, D. W., & Erdfelder, E. (2017). Linking process and measurement models of recognition-based decisions. Psychological Review, 124, 442–471. https://doi.org/10.1037/rev0000063
[Abstract] [BibTeX] [Data & R Scripts]When making inferences about pairs of objects, one of which is recognized and the other is not, the recognition heuristic states that participants choose the recognized object in a noncompensatory way without considering any further knowledge. In contrast, information-integration theories such as parallel constraint satisfaction (PCS) assume that recognition is merely one of many cues that is integrated with further knowledge in a compensatory way. To test both process models against each other without manipulating recognition or further knowledge, we include response times into the r-model, a popular multinomial processing tree model for memory-based decisions. Essentially, this response-time-extended r-model allows to test a crucial prediction of PCS, namely, that the integration of recognition-congruent knowledge leads to faster decisions compared to the consideration of recognition only—even though more information is processed. In contrast, decisions due to recognition-heuristic use are predicted to be faster than decisions affected by any further knowledge. Using the classical German-cities example, simulations show that the novel measurement model discriminates between both process models based on choices, decision times, and recognition judgments only. In a reanalysis of 29 data sets including more than 400,000 individual trials, noncompensatory choices of the recognized option were estimated to be slower than choices due to recognition-congruent knowledge. This corroborates the parallel information-integration account of memory-based decisions, according to which decisions become faster when the coherence of the available information increases. (PsycINFO Database Record (c) 2017 APA, all rights reserved)
@article{heck2017linking, title = {Linking Process and Measurement Models of Recognition-Based Decisions}, author = {Heck, Daniel W and Erdfelder, Edgar}, date = {2017}, journaltitle = {Psychological Review}, volume = {124}, pages = {442--471}, doi = {10.1037/rev0000063}, abstract = {When making inferences about pairs of objects, one of which is recognized and the other is not, the recognition heuristic states that participants choose the recognized object in a noncompensatory way without considering any further knowledge. In contrast, information-integration theories such as parallel constraint satisfaction (PCS) assume that recognition is merely one of many cues that is integrated with further knowledge in a compensatory way. To test both process models against each other without manipulating recognition or further knowledge, we include response times into the r-model, a popular multinomial processing tree model for memory-based decisions. Essentially, this response-time-extended r-model allows to test a crucial prediction of PCS, namely, that the integration of recognition-congruent knowledge leads to faster decisions compared to the consideration of recognition only—even though more information is processed. In contrast, decisions due to recognition-heuristic use are predicted to be faster than decisions affected by any further knowledge. Using the classical German-cities example, simulations show that the novel measurement model discriminates between both process models based on choices, decision times, and recognition judgments only. In a reanalysis of 29 data sets including more than 400,000 individual trials, noncompensatory choices of the recognized option were estimated to be slower than choices due to recognition-congruent knowledge. This corroborates the parallel information-integration account of memory-based decisions, according to which decisions become faster when the coherence of the available information increases. (PsycINFO Database Record (c) 2017 APA, all rights reserved)}, osf = {https://osf.io/4kv87}, keywords = {heckfirst,heckpaper,popularity\_bias} }
Generalized Processing Tree Models
More recently, we developed an alternative approach that assumes specific parametric distributions (e.g., Gaussian) for the component distributions of MPT-mixtures. These “Generalized Processing Tree (GPT) Models” are explained in:
- Heck, D. W., Erdfelder, E., & Kieslich, P. J. (2018). Generalized processing tree models: Jointly modeling discrete and continuous variables. Psychometrika, 83, 893–918. https://doi.org/10.1007/s11336-018-9622-0
[Abstract] [BibTeX] [Data & R Scripts] [GitHub]Multinomial processing tree models assume that discrete cognitive states determine observed response frequencies. Generalized processing tree (GPT) models extend this conceptual framework to continuous variables such as response times, process-tracing measures, or neurophysiological variables. GPT models assume finite-mixture distributions, with weights determined by a processing tree structure, and continuous components modeled by parameterized distributions such as Gaussians with separate or shared parameters across states. We discuss identifiability, parameter estimation, model testing, a modeling syntax, and the improved precision of GPT estimates. Finally, a GPT version of the feature comparison model of semantic categorization is applied to computer-mouse trajectories.
@article{heck2018generalized, title = {Generalized Processing Tree Models: {{Jointly}} Modeling Discrete and Continuous Variables}, author = {Heck, Daniel W and Erdfelder, Edgar and Kieslich, Pascal J}, date = {2018}, journaltitle = {Psychometrika}, volume = {83}, pages = {893--918}, doi = {10.1007/s11336-018-9622-0}, abstract = {Multinomial processing tree models assume that discrete cognitive states determine observed response frequencies. Generalized processing tree (GPT) models extend this conceptual framework to continuous variables such as response times, process-tracing measures, or neurophysiological variables. GPT models assume finite-mixture distributions, with weights determined by a processing tree structure, and continuous components modeled by parameterized distributions such as Gaussians with separate or shared parameters across states. We discuss identifiability, parameter estimation, model testing, a modeling syntax, and the improved precision of GPT estimates. Finally, a GPT version of the feature comparison model of semantic categorization is applied to computer-mouse trajectories.}, github = {https://github.com/danheck/gpt}, osf = {https://osf.io/fyeum}, keywords = {heckfirst} }